GSoC2023でGCC RustフロントエンドのUnicodeサポートに取り組んでいます。 先週、midterm eveluationが終わり、無事に通過することができました。
この記事では、時系列順に取り組んだことと今後について説明します。
現状
こんな感じで、ソースコード内で色々な文字を使うことができます。 識別子だけでなく、様々な空白や改行にも対応しています。 name mangingは未実装のため、非ASCII文字を名前に含む関数などのリンクには対応していません。
fn Русский() { let 日本語 = (); }
目次の代わりにに進捗を列挙しておきます。
これまでに取り組んだこと
UTF-8識別子のトークナイズ
Rustでは識別子は以下のような正規表現で表されます。
(XID_Start | '_') XID_Continue*
XID_StartとXID_Continueはそれぞれ英語アルファベットと英数字を拡張した属性と思っていただけると良いです。これらの属性はUnicodeのデータベースの一つであるDerivedCoreProperties.txtをルックアップすることで調べることができます。
これまで、gccrsは生文字列リテラル (r#"..."#)はサポートしていたため、部分的にUTF-8デコーダが使われていました。
このデコーダを識別子をトークナイズする際にも使うようにしました。
Unicodeでは、各文字に対して、一意の数であるコードポイントを定義しています。 もともと、コードポイントと属性のテーブルはlibcppというGCCのCプリプロセッサのコード上に存在していました。これを活用するために、libcppにテーブルを二部探索する関数を追加し、gccrsにリンクするようにしました。
lexer/parserのリファクタリング
UTF-8デコーダがlexerの一部でしか使えなかったので、ファイルからソースコードを読み込む時点でデコードを行うように改修しました。 lexer内ではcharを使って1つの文字を表していたため、全てしらみつぶしに置き換えるのが大変でした。
Rustはセルフホストしているため、このような明示的なUTF-8デコーダがコンパイラにないのが面白いです。
識別子への位置情報の追加
識別子の位置情報とは、ファイル名や行番号、列番号のことです。 これまでgccrs内部では、識別子と位置情報がデータ構造として一緒に扱われていませんでした。 そのためエラー出力(diagnostics)がユーザーに優しくないという短所がありました。 イメージとしては以下のような感じです。
before:
fn main() { ...
^
error: hoge
after:
fn main() { ...
^^^^
error: hoge
この作業自体はUnicode対応とは関係ありませんが、gccrsの予てからの課題だったので取り組みました。 パーサーやASTまわりのコードだけで数千~数万行あるので大変かと思っていましたが、意外と百行程度の変更で済みました。
UnicodeのNFC正規化
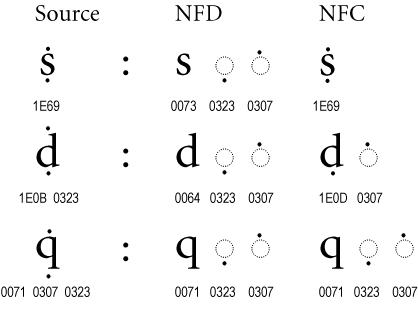
UnicodeのUAX#15という仕様書の中で、Unicodeのバイト列の正規化方法が定義されています。 正規化をすることで、同じように見えるがバイト列が異なる文字列を同じバイト列に変換することができ、文字列比較が簡単になります。
以下は正規化の例で、NFC以外にもNFD, NFKC, NFKDの三種類があります。(気になった方は調べてみてください。)
 https://unicode.org/reports/tr15/
https://unicode.org/reports/tr15/
Rustはソースコードに現れる識別子をNFCという形式に正規化することを定めています。 (ハングルを除く)文字列の正規化を行うはすでに実装できているため、今後はこれをパーサーに載せる予定です。 ちなみに、正規化においてハングルは音節文字の分解・合成を効率的に処理するため特別扱いされます。
実装には、正規化のリファレンス実装であるW3CのCharlintを参考にしました。 10年前からメンテされていなくて最新版のUnicodeに対応していないので、パッチを送ろうかと思っています。
また、Unicodeデータベースを利用するために、PythonでC++のヘッダーファイルのジェネレータを作りました。
これから
今後はナイーブな正規化の実装の最適化や、name manglingに必要なPunycode変換の実装を行っていく予定です。